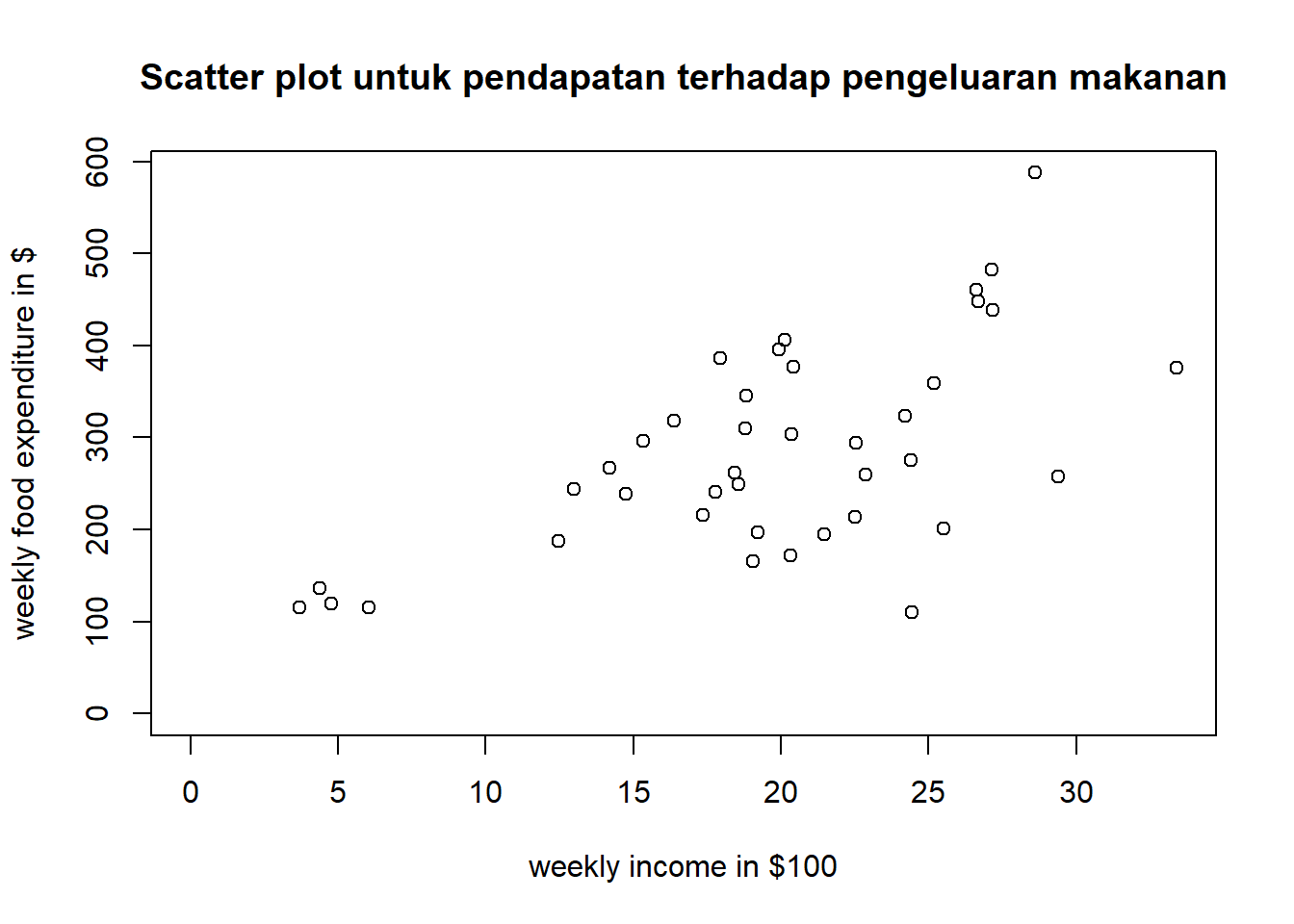
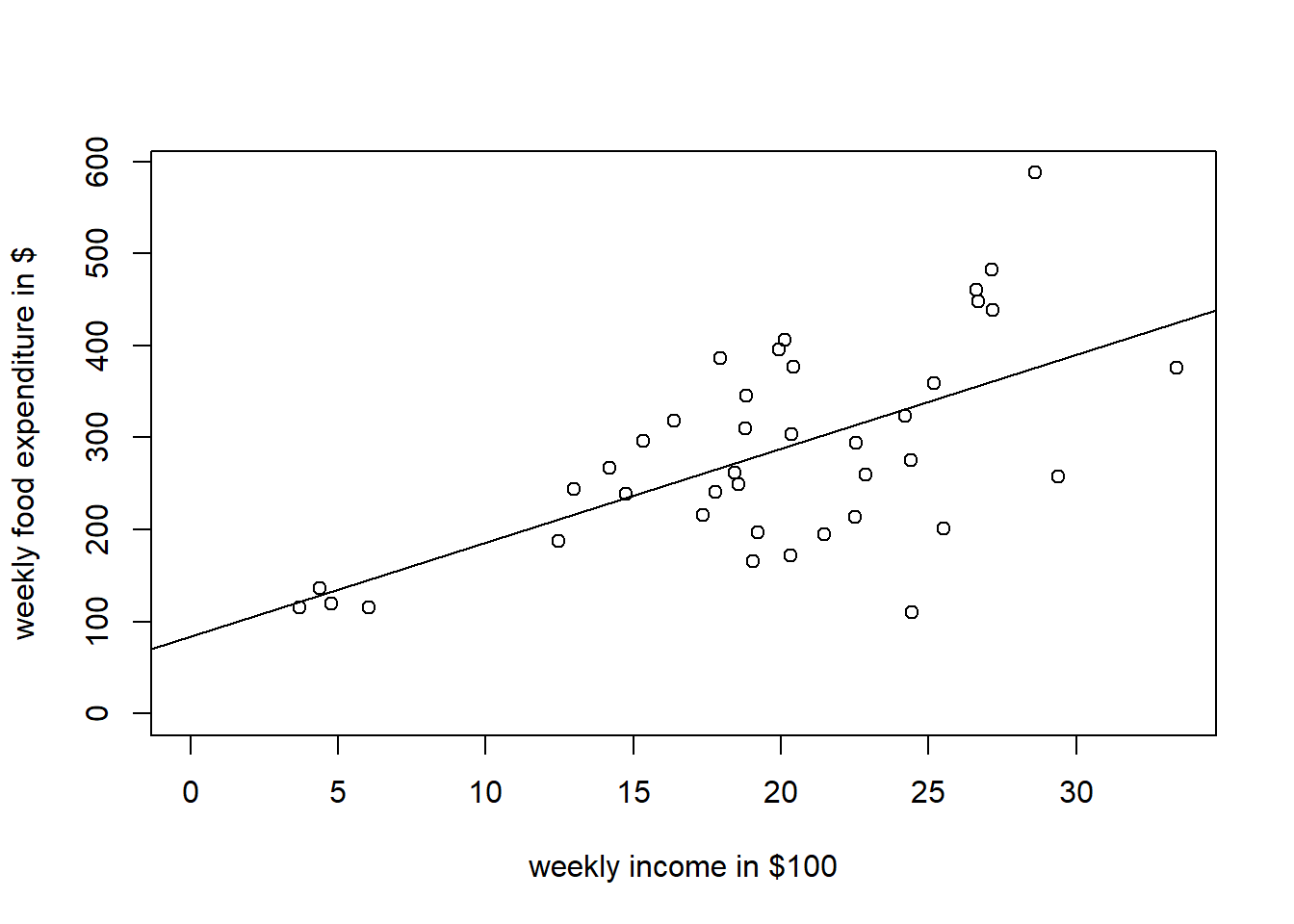
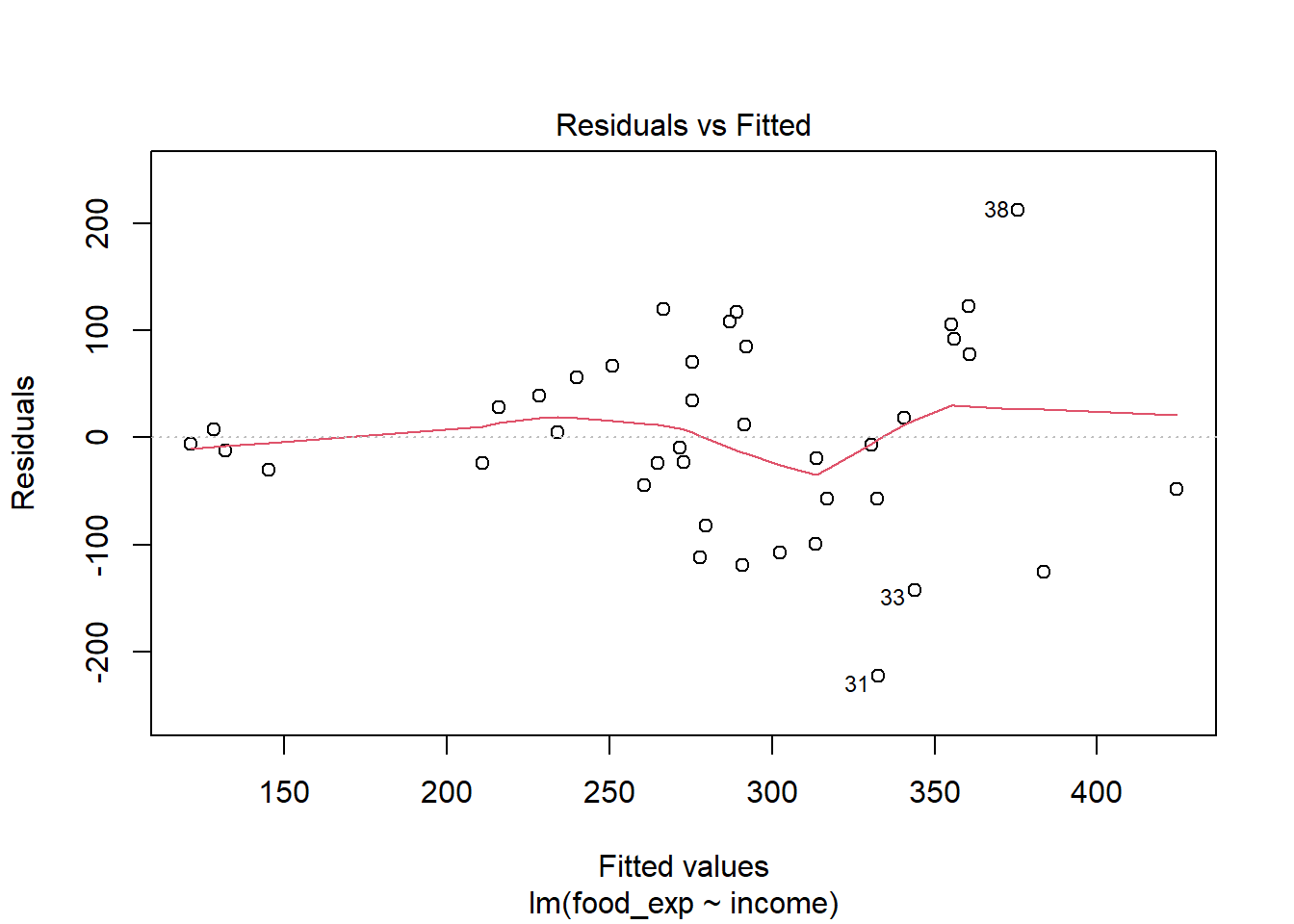
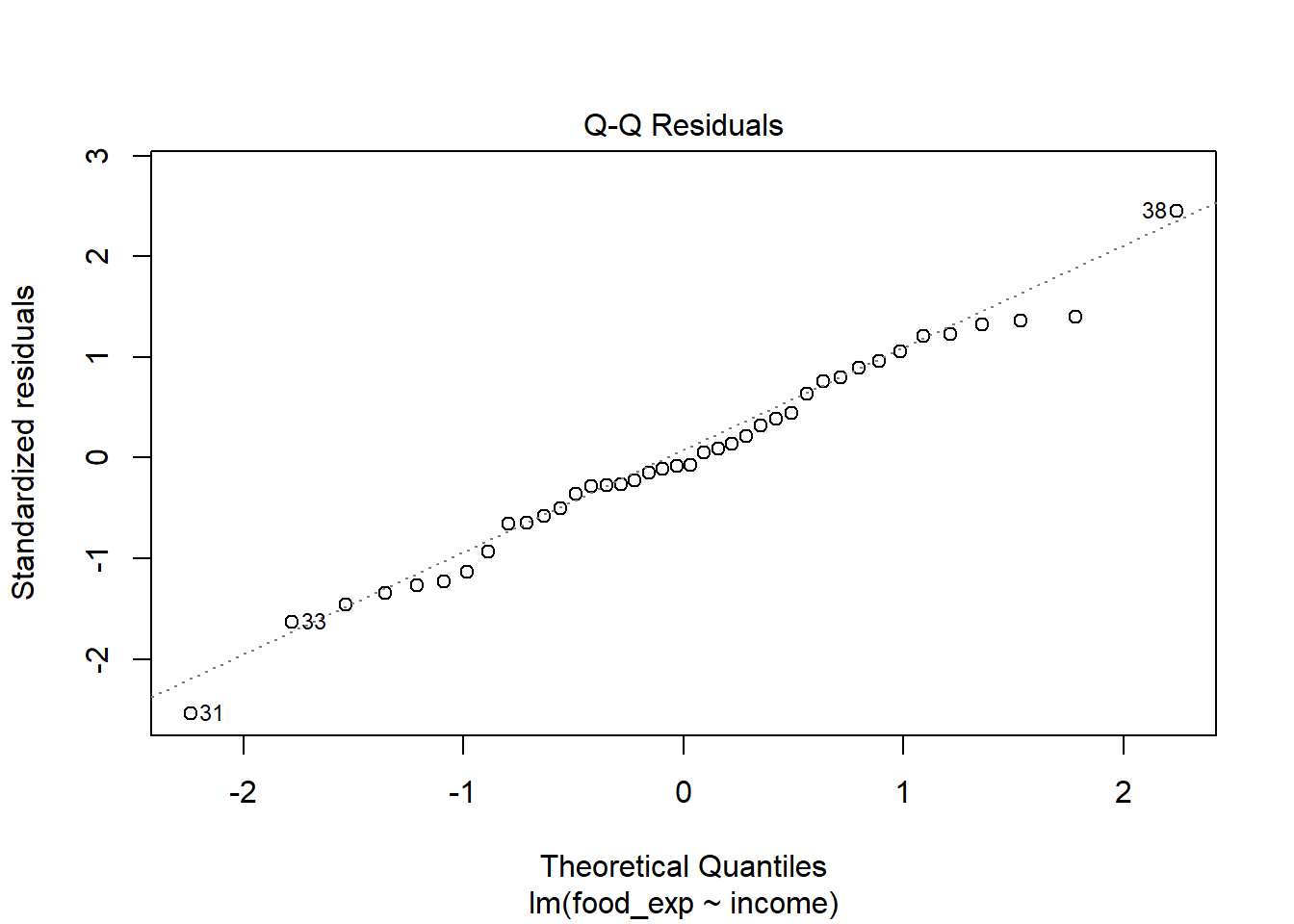
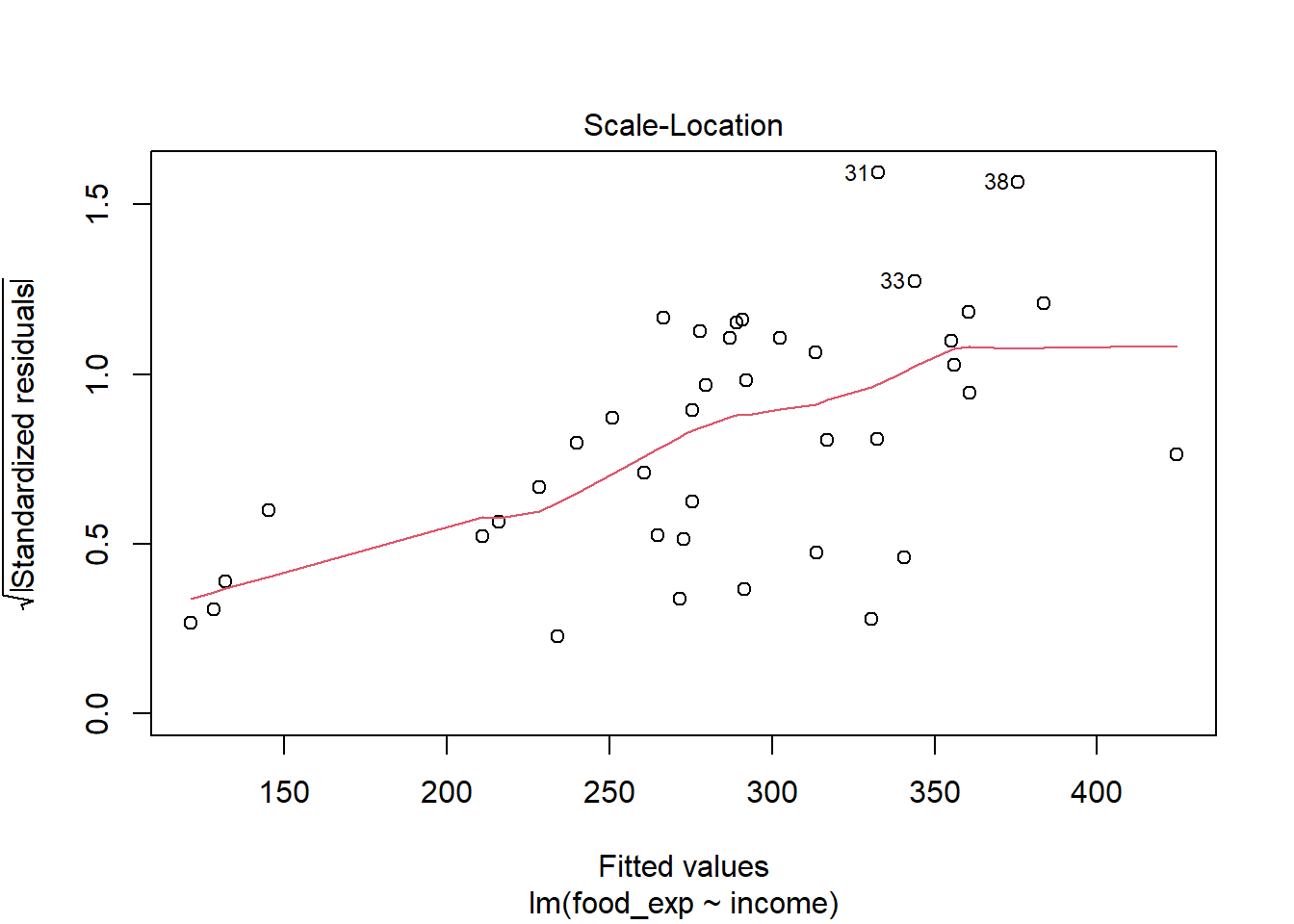
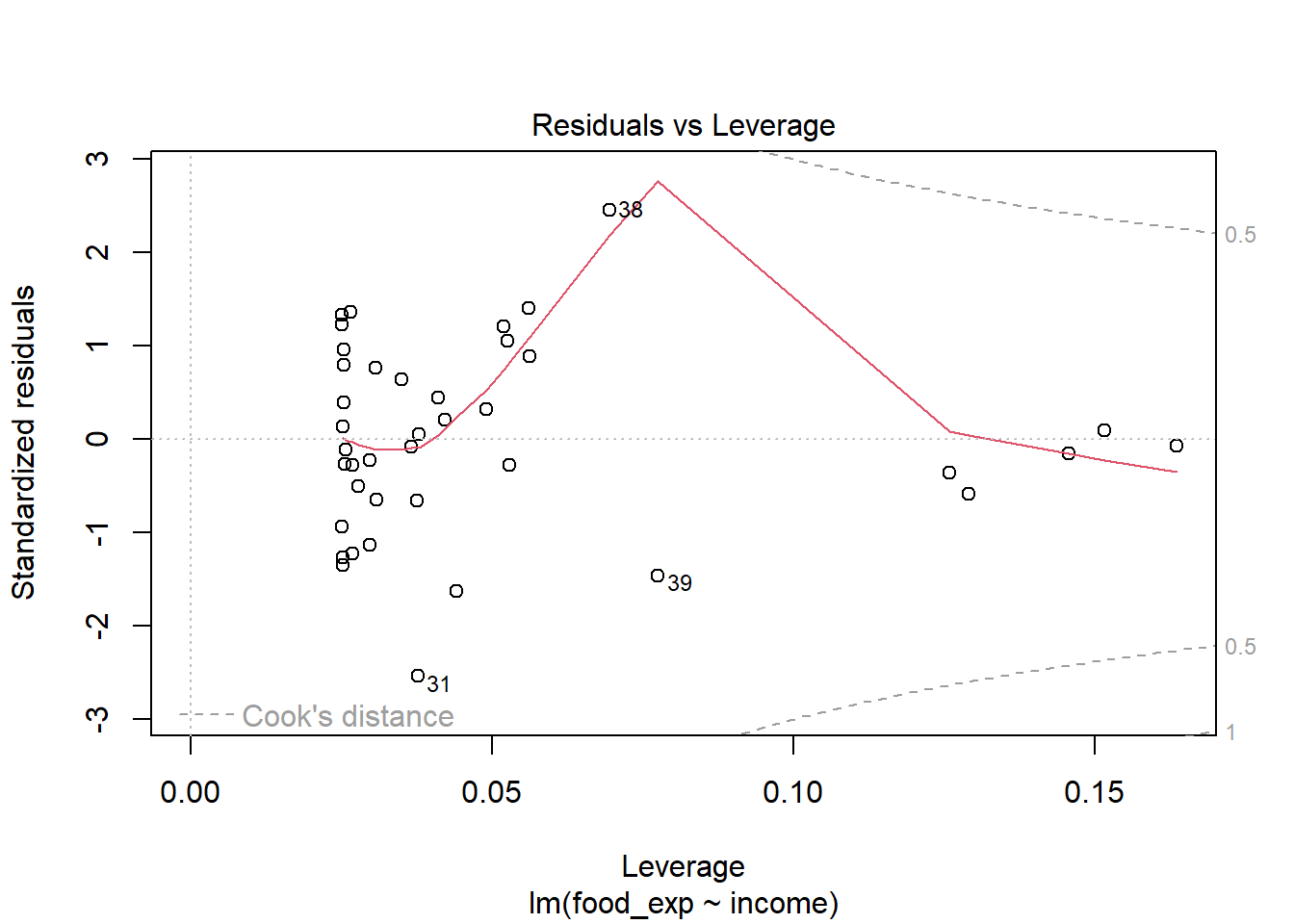
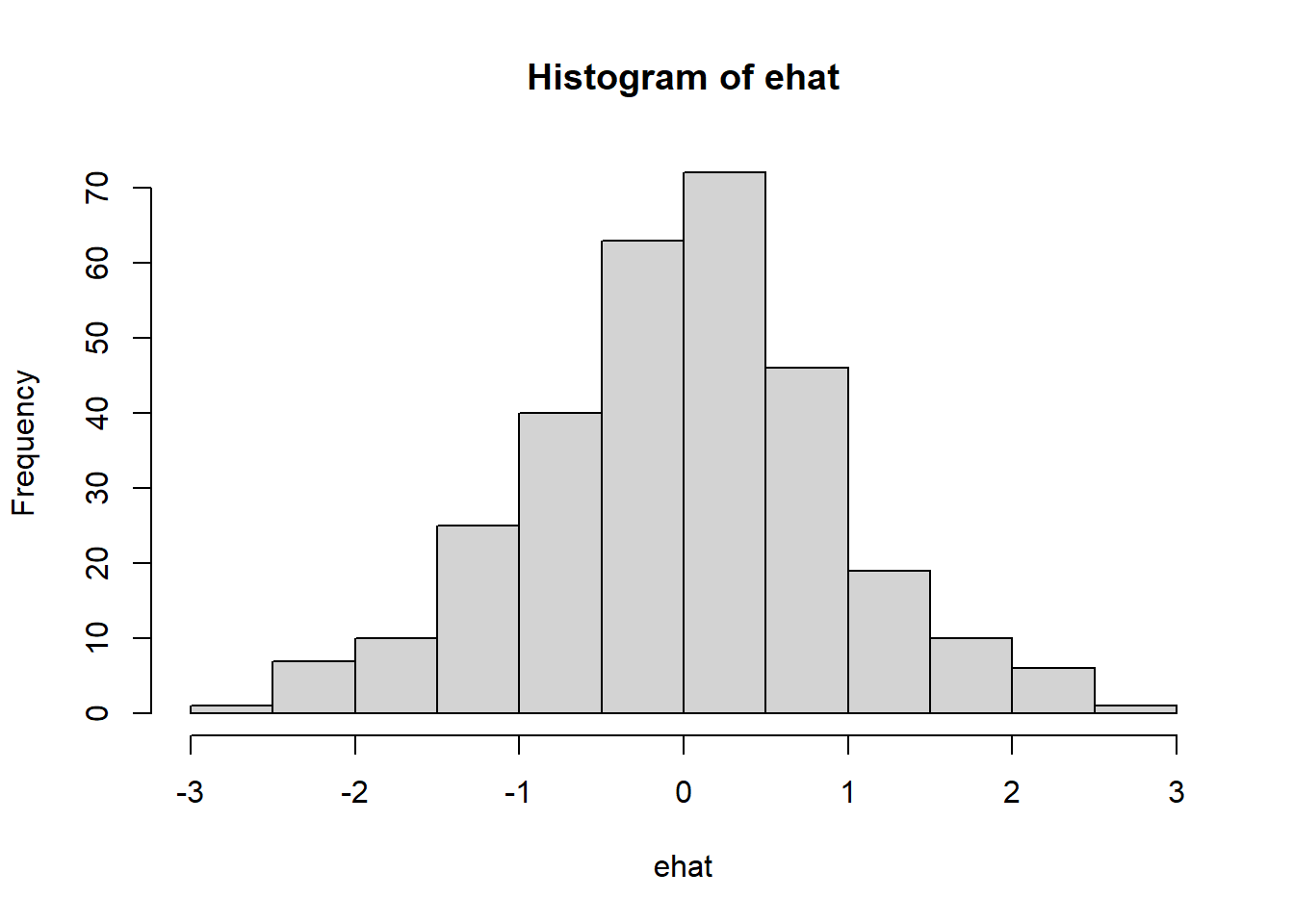
Data berjumlah 40 observasi. Variabel yang diamati ada 2. Data selengkapnya dapat diakses pada link yang disediakan.
Show the code
data("food", package="PoEdata")plot(food$income, food$food_exp, ylim=c(0, max(food$food_exp)), xlim=c(0, max(food$income)), xlab="weekly income in $100", ylab="weekly food expenditure in $", type ="p", main="Scatter plot untuk pendapatan terhadap pengeluaran makanan")
mod1<-lm(food_exp~income, data =food)b0<-coef(mod1)[[1]]b1<-coef(mod1)[[2]]smod1<-summary(mod1)smod1
Call:
lm(formula = food_exp ~ income, data = food)
Residuals:
Min 1Q Median 3Q Max
-223.025 -50.816 -6.324 67.879 212.044
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 83.416 43.410 1.922 0.0622 .
income 10.210 2.093 4.877 1.95e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 89.52 on 38 degrees of freedom
Multiple R-squared: 0.385, Adjusted R-squared: 0.3688
F-statistic: 23.79 on 1 and 38 DF, p-value: 1.946e-05
Show the code
plot(food$income, food$food_exp, xlab="weekly income in $100", ylab="weekly food expenditure in $", ylim=c(0, max(food$food_exp)), xlim=c(0, max(food$income)), type ="p")abline(b0,b1)
Artinya: 38.5 % proporsi variasi y yang dapat dijelaskan oleh model/variabel x.
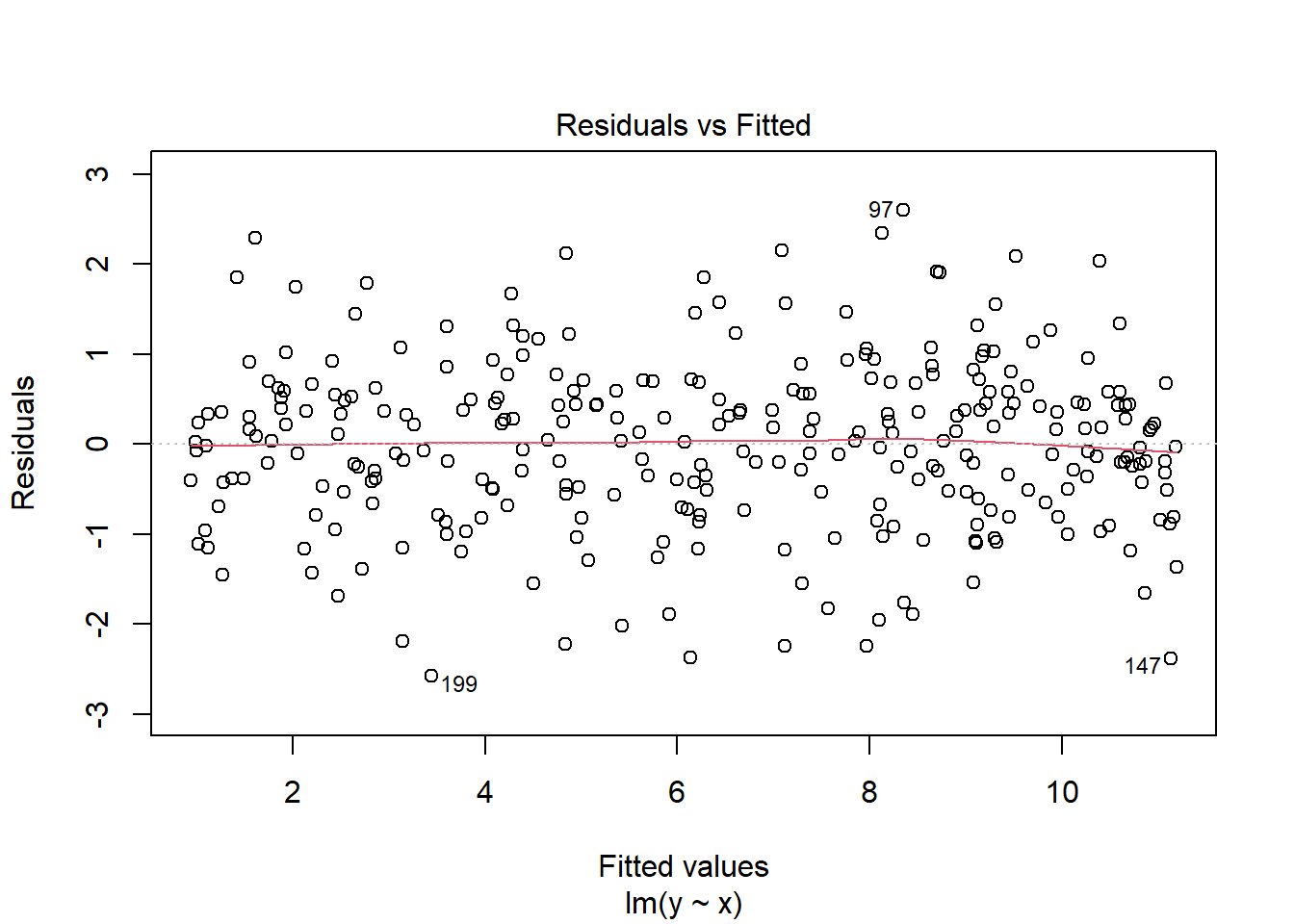
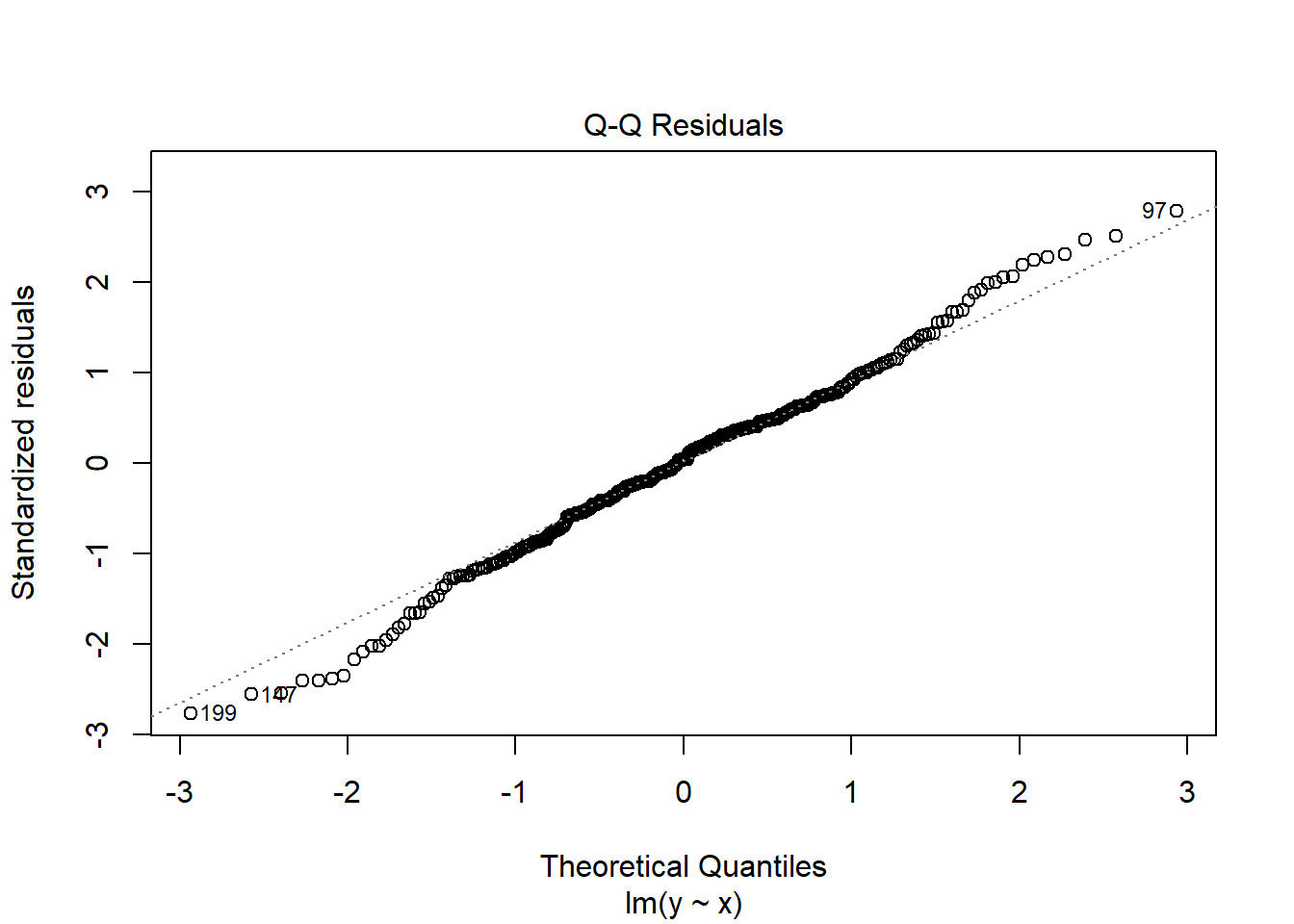
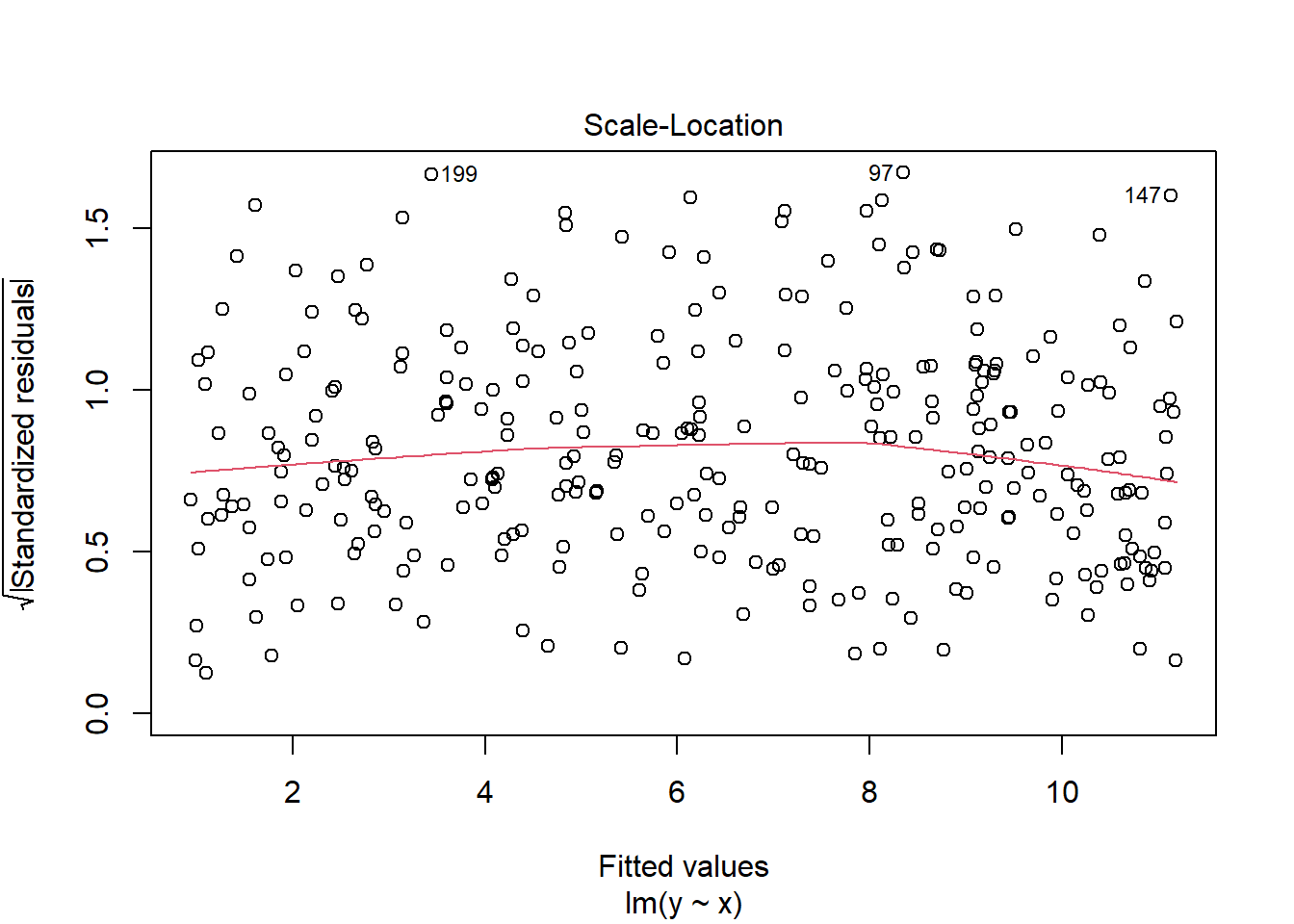
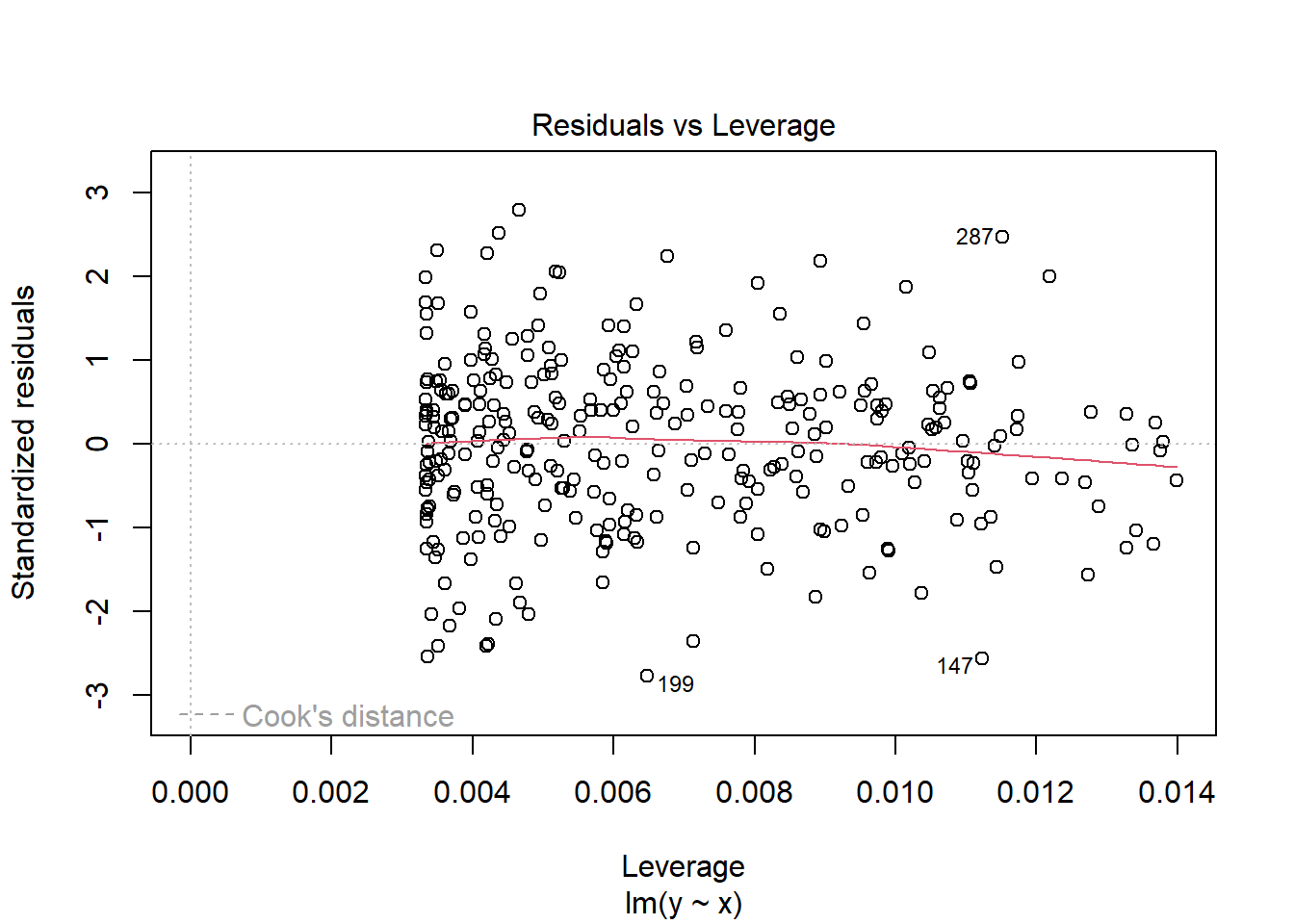
2.3.5 Contoh Pengecekan Asumsi yang sesuai/Ideal
Show the code
set.seed(12345)#sets the seed for the random number generatorx<-runif(300, 0, 10)e<-rnorm(300, 0, 1)y<-1+x+emod3<-lm(y~x)ehat<-resid(mod3)plot(x,ehat, xlab="x", ylab="residuals")
Setiap Terjadi Kenaikan Income sebesar USD 100 (Kenaikannya sebesar 1 satuan, tetapi satuan x dalam hal ini income adalah USD 100), terjadi kenaikan pengeluaran makanan sebesar USD 10,21 (satuan y dalam hal ini adalah USD).
Extras: Model Log-log
Show the code
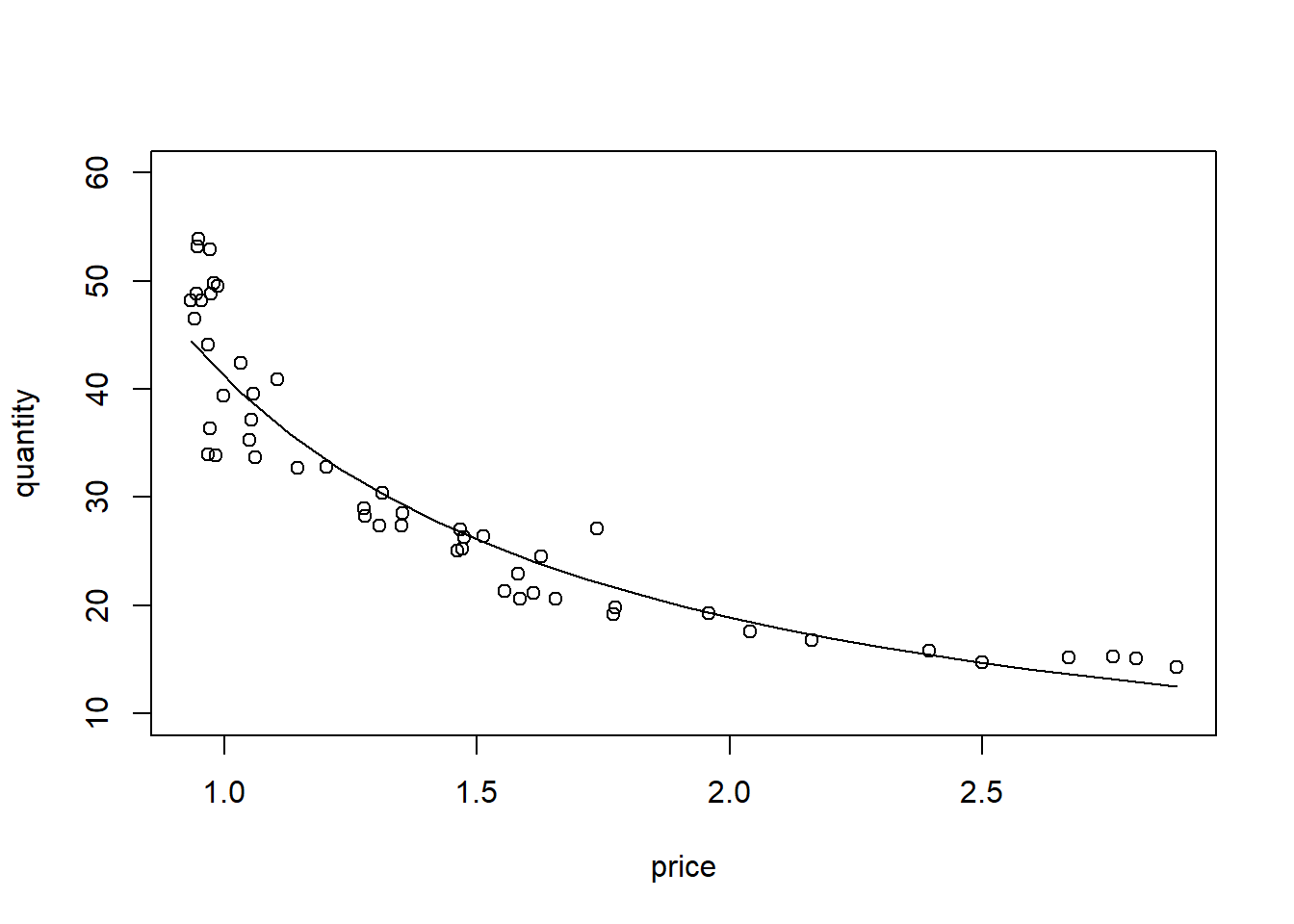
# Calculating log-log demand for chickendata("newbroiler", package="PoEdata")mod6<-lm(log(q)~log(p), data=newbroiler)b1<-coef(mod6)[[1]]b2<-coef(mod6)[[2]]smod6<-summary(mod6)tbl<-data.frame(xtable(smod6))kable(tbl, caption="Model Hubungan Harga terhadap Permintaan Ayam")
Model Hubungan Harga terhadap Permintaan Ayam
Estimate
Std..Error
t.value
Pr…t..
(Intercept)
3.716944
0.0223594
166.23619
0
log(p)
-1.121358
0.0487564
-22.99918
0
Show the code
# Drawing the fitted values of the log-log equationngrid<-20# number of drawing points xmin<-min(newbroiler$p)xmax<-max(newbroiler$p)step<-(xmax-xmin)/ngrid# grid dimensionxp<-seq(xmin, xmax, step)predicty=exp(b1+b2*log(xp))plot(newbroiler$p, newbroiler$q, ylim=c(10,60), xlab="price", ylab="quantity")lines(predicty~xp, lty=1, col="black")
Extras 2: Model dengan Asumsi Homoskedastisitas yang terlanggar
Karena adanya heteroskedastisitas membuat kesalahan standar kuadrat terkecil menjadi keliru, maka diperlukan metode lain untuk menghitung Regresi.
Show the code
library(car)foodeq<-lm(food_exp~income,data=food)kable(tidy(foodeq),caption="Regular standard errors in the 'food' equation")
Regular standard errors in the ‘food’ equation
term
estimate
std.error
statistic
p.value
(Intercept)
83.41600
43.410163
1.921578
0.0621824
income
10.20964
2.093263
4.877381
0.0000195
Show the code
cov1<-hccm(foodeq, type="hc1")#needs package 'car'food.HC1<-coeftest(foodeq, vcov.=cov1)kable(tidy(food.HC1),caption="Robust (HC1) standard errors in the 'food' equation")
Robust (HC1) standard errors in the ‘food’ equation
term
estimate
std.error
statistic
p.value
(Intercept)
83.41600
27.463748
3.037313
0.0042989
income
10.20964
1.809077
5.643566
0.0000018
Show the code
w<-1/food$incomefood.wls<-lm(food_exp~income, weights=w, data=food)vcvfoodeq<-coeftest(foodeq, vcov.=cov1)kable(tidy(foodeq), caption="OLS estimates for the 'food' equation")
OLS estimates for the ‘food’ equation
term
estimate
std.error
statistic
p.value
(Intercept)
83.41600
43.410163
1.921578
0.0621824
income
10.20964
2.093263
4.877381
0.0000195
Show the code
kable(tidy(food.wls), caption="WLS estimates for the 'food' equation")
WLS estimates for the ‘food’ equation
term
estimate
std.error
statistic
p.value
(Intercept)
78.68408
23.788722
3.307621
0.0020641
income
10.45101
1.385891
7.541002
0.0000000
Show the code
kable(tidy(vcvfoodeq),caption="OLS estimates for the 'food' equation with robust standard errors")
OLS estimates for the ‘food’ equation with robust standard errors